In the fast-paced world of data engineering, staying ahead of the competition is crucial. Traditional ETL (Extract, Transform, Load) pipelines often face challenges with collaboration, agility, and scalability. However, the rise of DataOps has revolutionized the way organizations handle data workflows. In this blog, we will delve into the concept of DataOps and how it enhances collaboration and agility in ETL pipelines, empowering data engineers to optimize data processing and analysis for improved business outcomes.
What is DataOps?
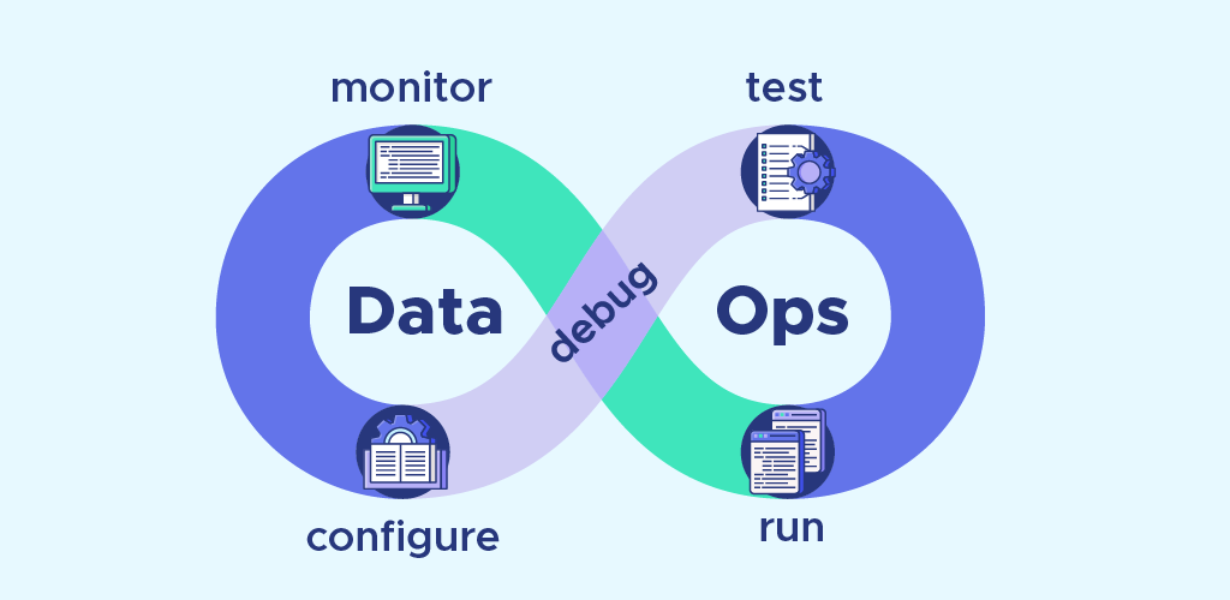
DataOps: Streamlining Data Engineering
DataOps, a combination of “Data” and “Operations,” is an approach that aligns data engineering, data integration, and data delivery with the principles of DevOps. It emphasizes collaboration, automation, and continuous delivery to optimize data pipelines and achieve faster insights. DataOps fosters a culture of collaboration among data engineers, data scientists, and business stakeholders, ensuring that data flows seamlessly across the organization.
The Role of Data Engineer in DataOps
Unraveling the Data Engineer’s Role
Data engineers play a pivotal role in the success of DataOps. They are responsible for designing, building, and maintaining data pipelines. Their tasks include data extraction from various sources, transforming the data into a suitable format, and loading it into the target systems. Data engineers also need to ensure data quality, data security, and adherence to compliance standards.
Advantages of Adopting DataOps
Accelerating Insights: The DataOps Advantage
Collaboration and Efficiency: DataOps breaks down silos between different teams, fostering better collaboration. When data engineers, data scientists, and business analysts work in harmony, it streamlines the decision-making process and accelerates insights.
Agility and Flexibility: With DataOps, organizations can adapt to changing data requirements swiftly. It allows data engineers to handle complex data scenarios efficiently and make real-time adjustments to the data pipelines as needed.
Continuous Delivery: DataOps enables continuous integration and continuous delivery (CI/CD) principles, ensuring that data pipelines are updated, tested, and deployed regularly. This leads to a faster time-to-value for data-driven initiatives.
Enhanced Data Governance: DataOps emphasizes data governance and compliance, ensuring that data is managed securely and responsibly. This fosters trust in the data and improves decision-making.
Key Components of DataOps
Building Blocks for Success
Automated Testing: DataOps relies heavily on automated testing to ensure data accuracy and reliability. Automated testing reduces human errors and helps in identifying issues early in the development process.
Version Control: Similar to software development, data pipelines should be version-controlled. This enables tracking changes, rolling back to previous versions, and collaborating effectively.
Monitoring and Alerting: DataOps demands real-time monitoring and alerting mechanisms to promptly identify and address any issues that might arise during data processing.
Containerization and Orchestration: Containerization technologies like Docker and orchestration tools like Kubernetes make it easier to manage and deploy data pipelines at scale.
Best Practices for Implementing DataOps
Roadmap to Success
Adopt Agile Methodology: Implement Agile practices in your data engineering team to foster collaboration, iterative development, and quick feedback loops.
Empower Self-Service Analytics: Enable data scientists and analysts to access and analyze data independently, reducing dependency on data engineers for every query.
Invest in Data Quality: Data quality is paramount in DataOps. Implement data validation and cleansing processes to ensure high-quality, reliable data.
Promote Cross-Functional Training: Encourage cross-functional training among data engineering, data science, and business teams to improve mutual understanding and cooperation.
Final Words
In the age of data-driven decision-making, DataOps offers a groundbreaking approach to revolutionize ETL pipelines. By enhancing collaboration and agility, DataOps empowers data engineers to build robust and efficient data pipelines, enabling organizations to extract maximum value from their data assets.
Commonly Asked Questions
Q1: What skills does a data engineer need in a DataOps environment?
A data engineer in a DataOps environment should have strong programming skills, knowledge of data modeling, proficiency in SQL, and experience with cloud platforms and containerization technologies.
Q2: How does DataOps impact data security?
DataOps emphasizes data governance and compliance, leading to improved data security and responsible data management practices.
Q3: Can DataOps handle big data processing?
Yes, DataOps can handle big data processing effectively, as it prioritizes scalability and flexibility in data pipelines.
Q4: What role does automation play in DataOps?
Automation is a critical aspect of DataOps, as it reduces manual intervention, speeds up development cycles, and minimizes errors.
Q5: How does DataOps facilitate faster time-to-insights?
DataOps encourages continuous delivery and real-time adjustments, ensuring that insights are delivered quickly to stakeholders.

{kind=link}